¶ Detect Palmaceas
Este projeto inclui um serviço de inferência integrado com PyTorch, WANDB, RabbitMQ e MongoDB. Este processo ocorre da seguinte forma:
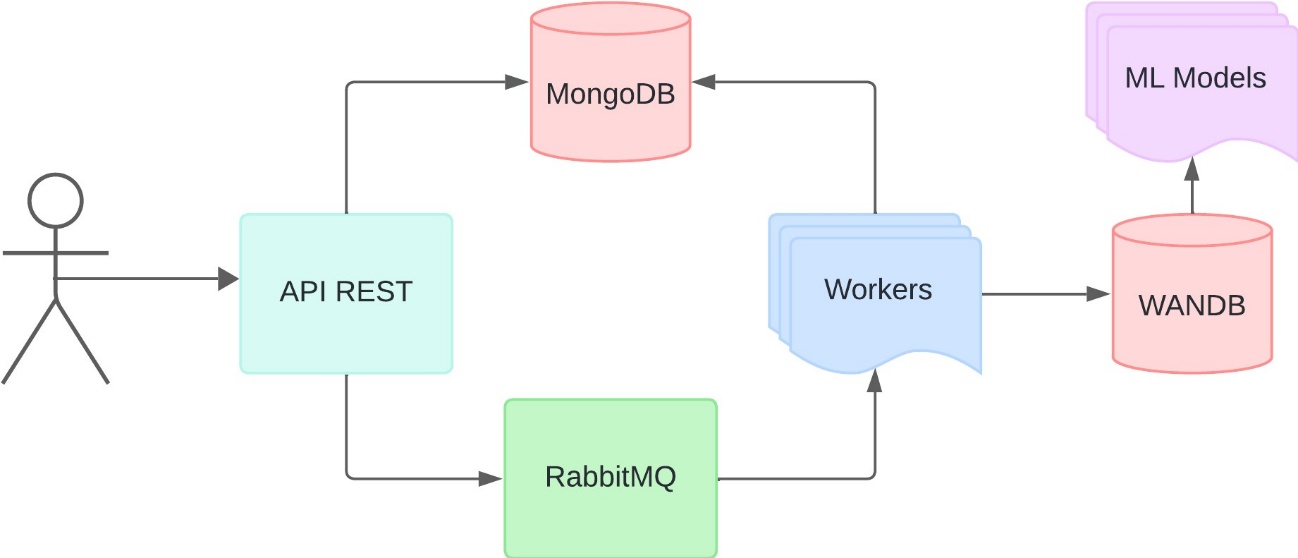
O MongoDB é um banco de dados NoSQL amplamente utilizado para armazenamento de dados em documentos JSON-like. É uma escolha popular devido à sua flexibilidade, escalabilidade e capacidade de trabalhar com grandes volumes de dados não estruturados. Ele suporta consultas avançadas, índices e agregações, sendo ideal para aplicações modernas e baseadas em nuvem.
Para mais informações, acesse: https://www.mongodb.com
RabbitMQ é um message broker (gerenciador de mensagens) que permite a comunicação entre diferentes sistemas ou serviços por meio do envio e recebimento de mensagens de maneira assíncrona. Ele é amplamente utilizado em sistemas distribuídos para implementar filas de mensagens e sistemas de publicação/assinatura.
Site oficial: https://www.rabbitmq.com/
Weights & Biases (W&B) é uma plataforma que auxilia no rastreamento de experimentos de machine learning, visualização de métricas, gerenciamento de hiperparâmetros e monitoramento de modelos. É amplamente usado para colaboração em projetos de IA e análise de desempenho de modelos.
Site oficial: https://wandb.ai/
¶ Funcionamento do modelo
Para a implementação do modelo, existe a implementação de uma classe chamada PalmDetectionModel, que realiza a detecção de objetos em imagens, especificamente árvores e palmeiras, utilizando o modelo YOLO (You Only Look Once). Ele é estruturado de forma a integrar diferentes etapas de processamento de imagens, carregamento do modelo e formatação dos resultados.
A classe começa com a definição de algumas bibliotecas essenciais, como o wandb para carregar o modelo diretamente de um artefato armazenado na plataforma
Weights & Biases, e o ultralytics, que fornece a funcionalidade do YOLO. Além disso, outras bibliotecas, como torch e PIL, são usadas para manipulação de dispositivos e processamento de imagens, enquanto o numpy ajuda no tratamento de dados numéricos. Um dicionário, DETECTION_CLASSES, é definido para mapear os IDs das classes detectadas pelo modelo para nomes descritivos, como "Tree" e "Palm".
Na inicialização da classe, o método __init__ determina o dispositivo a ser utilizado, seja GPU ou CPU, e realiza o download do modelo mais recente do YOLO a partir do W&B. O modelo é então carregado e movido para o dispositivo selecionado, e a versão do artefato é armazenada para referência futura.
O método principal, detect, é responsável por realizar a detecção de objetos em uma imagem fornecida. Ele aceita imagens em bytes ou como arrays NumPy e converte-as em um formato apropriado. A imagem é redimensionada para as dimensões exigidas pelo YOLO (640x640 pixels) antes de ser passada para o modelo para inferência. O YOLO retorna caixas delimitadoras (bounding boxes) e classes detectadas, que são processadas para desenhar essas caixas na imagem redimensionada, incluindo os nomes das classes. As caixas delimitadoras são convertidas de coordenadas normalizadas para absolutas para facilitar o desenho e o entendimento visual. Durante o processo, o método organiza os objetos detectados em uma lista e armazena a contagem de cada classe em um dicionário.
Além disso, a imagem com as caixas desenhadas é convertida para uma string codificada em Base64 por meio de um método auxiliar, _image_to_base64, o que facilita a transmissão ou armazenamento do resultado. O método detect retorna um dicionário contendo informações detalhadas sobre os objetos detectados, incluindo as coordenadas normalizadas das caixas delimitadoras, a contagem de classes, a imagem anotada em Base64 e metadados sobre a versão do modelo usado. Ele também retorna informações sobre os tamanhos original e redimensionado da imagem.
No geral, o código de inferência fornece uma solução modular e eficiente para detectar objetos em imagens, gerando saídas bem formatadas e fáceis de integrar em outras aplicações. A estrutura permite adaptações para detectar outras classes ou utilizar outros modelos YOLO, tornando-o altamente reutilizável.
¶ Para rodar o projeto:
pip install -r requirements.txt
python3 worker.py
¶ Para rodar via docker:
docker ps
docker build -t detect-palmaceas-worker .
¶ Instalar suporte a GPUs no docker
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | gpg --dearmor -o /usr/share/keyrings/nvidia-toolkit.gpg curl -fsSL https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-co ntainer-toolkit.list | tee /etc/apt/sources.list.d/nvidia-toolkit.list
sed -i -e "s/^deb/deb \[signed-by=\/usr\/share\/keyrings\/nvidia-toolkit.gpg\]/g" /etc/apt/sources.list.d/nvidia-toolkit.list
apt update
apt -y install nvidia-container-toolkit
systemctl restart docker
¶ Executar seu contêiner de trabalho
docker run --gpus all --name detect-palmaceas-worker --network host \ -e RABBITMQ_URL="localhost" \
-e RABBITMQ_PORT="5672" \
-e RABBITMQ_LOGIN="guest" \
-e RABBITMQ_PASSWORD="guest" \
-e MONGODB_URL="mongodb://localhost:27017" \
-e MONGODB_USERNAME="admin" \
-e MONGODB_PASSWORD="admin" \
-e MONGODB_DB_NAME="baites-api-db" \
-e WANDB_API_KEY="API_KEY_HERE" \
detect-palmaceas-worker:latest \